
TBD
Writing a Managed FreeSWITCH Module to Add SigHup Support in Windows
The purpose of this post is twofold: the first part is a tutorial on how to build and deploy a managed FreeSWITCH module, the second part is about on-demand log rotation support for FreeSWITCH in Windows environment.
The official docs of mod_managed combined with the source of the Demo project give a good description of the process but a key point is missing. Here is what worked for me step-by-step
- Clone the FS source (branch V1.8 in my case) and build it
- Locate FreeSWITCH.Managed.csproj under src/mod/languages/mod_managed/managed and build it
- Create new .Net project with a Class Library output type and .Net Framework 4.5 target framework.
- Reference the FreeSWITCH.Managed.dll built at step 2
- Create a new class and implement the FreeSWITCH.IApiPlugin interface
- Build and copy the output dll along with its dependencies (FreeSWITCH.Managed.dll and any other dependency you have added) to the FS mod/managed directory
- Enable mod_managed in FS modules.conf
- (Re)start FreeSwitch and check the log for the module loading
This was easy, but what is inside a module? There are a lot of module types I won’t go into detail I will give a very simple example instead. There is no built-in support for rotating the log files on a daily basis. This is accomplished by sending a HUP signal to the process
kill -HUP `cat /usr/local/freeswitch/run/freeswitch.pid`
Such a command is usually scheduled with CRON or a similar tool.
This won’t work on windows, here is where a custom module could help. After some source reading, it turned out that the signal translates into an internal event. So the module will be very simple: trigger the same event!
var evt = new Event("TRAP", null);
evt.AddHeader("Trapped-Signal", "HUP");
evt.Fire();
The full source can be found at https://github.com/rucc/ModSigHup
Usage from FS cli:
managed SigHup
Usage from windows cli:
fs_cli.exe -p secret -x "managed sighup"
For the best results remove the rollover and maximum-rotate params from logfile.conf
Transcoding in Freeswitch from Dialogic ADPCM to G711
I have received a strange error report after deploying the new Freeswitch based CTI system: The playback quality of certain sound files is low. After some research and detail request, we could locate such a file. First surprise: the file plays well in dev environment and the sound quality degrades during playback in the test environment. At the beginning it is fine then it starts to get worse and worse after a couple of seconds in a seemingly consistent way. What the heck? Key observations:
- All the files are .vox files (Dialogic ADPCM with 8KHz sampling and 4bit sample size)
- Just a small subset of all files is involved in the issue
- The issue can be reproduced in a consistent way
- These files have perfect quality when played back locally
To find out what is exactly happening it is always a good idea to look into the network traffic. Once again Wireshark comes to the rescue (thanks again Wireshark, you have made my life easier so many times). Once I got my hands on a network dump file recorded on the server, I’ve immediately checked the RTP stream quality (Telephony -> RTP Streams -> Stream analysis), everything is fine. There is a wonderful feature in Wireshark which plays back the sound from the recorded RTP stream, awesome! Let’s see it! Something is very strange on the waveform visualizer:
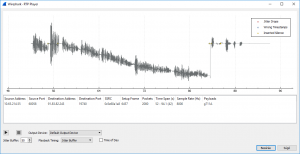
I have never seen something like this before. It looks like as if the zero level of the sound wave is shifting away from the reference zero.
To see what is really going on, I had to dig deeper. Fortunately, Freeswitch is open source and the decoding code can be isolated easily. I have extracted the decoding code and started to play with it. First I decoded the sound file and saved the output to a csv file, and imported it to an Excel sheet to visualize the waveform from the raw data.
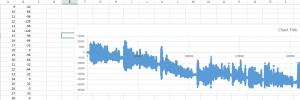
Column A is sample index, col B is the decoder output. Same as the one seen in WireShark. Does this output make any sense? I decided to try NAudio for playing the raw PCM data. It is fairly simple:
//open vox file //decode it (4 bit adpcm samples -> 16 bit raw pcm samples) to byte array //init memorystream from decodec byte array var rs = new RawSourceWaveStream(ms, new WaveFormat(8000, 16, 1)); var wo = new WaveOutEvent(); wo.Init(rs); wo.Play();
And the sound quality is perfect! This was a surprise to me, I expected to hear some sort of distortion when the wave gets near the lower quantization limit (Int16 min value).
But it explains why the quality is bad for such a file in the prod environment.: The codec used in the captured call was G711u which is a lossy compression format providing good quality where it is important for human sound perception (low and middle parts of the quantization range) and bad quality where it is less important (near the limits of the range). As the wave shifts towards the negative limit, the G711 encoding adds more and more detail loss. And it turns out that in the dev environment used a different codec, after making G711u the only codec available the issue gets easy to reproduce in the dev environment as well.
But why does the shifting happen? When the file is opened with SoX it says there are state errors during decoding.
sox -c 1 -r 8000 -b 4 -t vox ./suspect.vox converted.wav sox.exe WARN adpcms: ./suspect.vox: ADPCM state errors: 39
Vox is an adaptive format where not all inputs are valid. A series of vox samples is invalid if the decoded output does not fit into a 16 bit signed int (when decoding to 16 bit raw PCM). Sox suggests that the file is corrupt.
But it is contradicted by the fact that this file plays perfectly well with Dialogic HMP software under the same circumstances. How is it possible? There must be some difference between the way FreeSwitch and Dialogic HMP decodes the .vox files. Fortunately, a paper about the algorithm is available. It is a bit hardware oriented, but sufficient to implement it. This is my letter-to-letter implementation of what’s in the paper (C#):
public class VoxCoder
{
static Int32[] ss_idx_chg_map = { -1, -1, -1, -1, 2, 4, 6, 8 };
static Int32[] step_sizes =
{
16, 17, 19, 21, 23, 25, 28, 31, 34, 37, 41, 45,
50, 55, 60, 66, 73, 80, 88, 97, 107, 118, 130, 143,
157, 173, 190, 209, 230, 253, 279, 307, 337, 371, 408, 449,
494, 544, 598, 658, 724, 796, 876, 963, 1060, 1166, 1282, 1411, 1552
};
int curr_ss_idx = 0;
short last_output = 0;
public byte encode (Int16 pcmsample)
{
pcmsample = (Int16)(pcmsample >> 4); //scale to 12 bit space
var dn = pcmsample - last_output;
var ssn = step_sizes[curr_ss_idx];
byte b3 = 0, b2 = 0, b1 = 0, b0 = 0;
if (dn < 0) { b3 = 1; dn *= -1; } if (dn >= ssn)
{
b2 = 1;
dn = dn - ssn;
}
if (dn >= ssn / 2)
{
b1 = 1;
dn = dn - ssn / 2;
}
if (dn >= ssn / 4)
{
b0 = 1;
}
var ln = 0b1000 * b3 + 0b100 * b2 + 0b10 * b1 + b0;
var ret = (byte)ln;
decode(ret);
return ret;
}
public Int16 decode (byte voxSample)
{
var ssn = step_sizes[curr_ss_idx];
byte b3 = (byte)((voxSample & 0b1000) / 0b1000);
byte b2 = (byte)((voxSample & 0b100) / 0b100);
byte b1 = (byte)((voxSample & 0b10) / 0b10);
byte b0 = (byte)(voxSample & 0b1);
short dn = (short) ((ssn * b2) + (ssn / 2 * b1) + (ssn / 4 * b0) + ssn / 8);
if (b3 == 1)
{
dn *= -1;
}
var xn = (short) (last_output + dn);
last_output = xn;
curr_ss_idx += ss_idx_chg_map[voxSample & 0b111];
if (curr_ss_idx < 0) { curr_ss_idx = 0; } if (curr_ss_idx > step_sizes.Length - 1)
{
curr_ss_idx = step_sizes.Length - 1;
}
var ret = xn << 4;
return (Int16)ret;
}
}
The paper defines the algorithm to operate on 12 bit wide samples, so we need to scale it up to 16-bit space, that’s why the <<4 shifts are there for. I am going to refer to this algorithm as ‘Dialogic strict’ from now on. Let’s decode the file with this version:
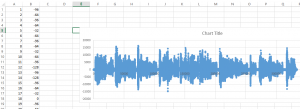
Flawless. So the file is not corrupt after all. But what is the difference between the two implementations? I wrote a small script to decode the file with both versions sample by sample and set a breakpoint with the condition that the two decoder outputs aren’t equal. Gotcha! The two versions give different output for the following case:
input sample: 9 step index: 7 last output: 672
Here is how the other decoder is implemented (libsndfile C++ ):
typedef struct
{
int mask ;
int last_output ;
int step_index ;
int max_step_index ;
int const * steps ;
int errors ;
int code_count, pcm_count ;
unsigned char codes [IMA_OKI_ADPCM_CODE_LEN] ;
short pcm [IMA_OKI_ADPCM_PCM_LEN] ;
} IMA_OKI_ADPCM ;
static int const oki_steps [] = /* ~12-bit precision */
{ 256, 272, 304, 336, 368, 400, 448, 496, 544, 592, 656, 720, 800, 880, 960,
1056, 1168, 1280, 1408, 1552, 1712, 1888, 2080, 2288, 2512, 2768, 3040, 3344,
3680, 4048, 4464, 4912, 5392, 5936, 6528, 7184, 7904, 8704, 9568, 10528,
11584, 12736, 14016, 15408, 16960, 18656, 20512, 22576, 24832
} ;
static int const step_changes [] = { -1, -1, -1, -1, 2, 4, 6, 8 } ;
void ima_oki_adpcm_init ()
{
memset (state, 0, sizeof (*state)) ;
state->max_step_index = ARRAY_LEN (oki_steps) - 1 ;
state->steps = oki_steps ;
state->mask = arith_shift_left (~0, 4) ;
}
int adpcm_decode (IMA_OKI_ADPCM * state, int code)
{
int s ;
s = ((code & 7) << 1) | 1 ;
s = ((state->steps [state->step_index] * s) >> 3) & state->mask ;
if (code & 8)
s = -s ;
s += state->last_output ;
if (s < MIN_SAMPLE || s > MAX_SAMPLE)
{
int grace ;
grace = (state->steps [state->step_index] >> 3) & state->mask ;
if (s < MIN_SAMPLE - grace || s > MAX_SAMPLE + grace)
state->errors ++ ;
s = s < MIN_SAMPLE ? MIN_SAMPLE : MAX_SAMPLE ;
} ;
state->step_index += step_changes [code & 7] ;
state->step_index = SF_MIN (SF_MAX (state->step_index, 0), state->max_step_index) ;
state->last_output = s ;
return s ;
}
The steps are adjusted to fit the 16 bit wide unencoded samples (each step size is multiplied by 16). The difference in the implementation what makes the difference in the output is the way it multiplies the input with the current step size. It seems equivalent at first glance but the truncation errors do not come out the same:
input = 9; // which is -1 curr_step_idx = 7; // dia strict version: ssn = 31; // steps[curr_step_idx] dn = 31 / 4 + 31 / 8; // = 10 // other version: ssn = 496; // = 31 * 16 dn = 496 / 8; // = 186 dn &= mask; // = 176; // 176 / 16 = 11 // 11 != 10 // in other words 31/4 + 31/8 != 31*3/8
This seems a minor difference but still enough to shift the level of the whole file because these differences can add together.
I haven’t found any files which weren’t correctly decoded by the strict version so I changed the prod implementation and opened a beer. I was very happy that the problem got solved, until… We got a user report about bad playback quality with some old sound files recorded with Dialogic HMP software. It was actually the same problem but the other way around:
- The file is correctly decoded by the libsndfile algorithm and incorrectly with the dia strict.
- All the files play correctly on Dialogic software
- There are sound editors which decode one of the two files correctly (GoldWave, Sox) and there are editors which handle both files correctly (Cool edit)
But how do Cool edit and Dialogic achieve that? The decoder output of Cool edit cannot be compared to the versions directly but after examining it I have a strange feeling as if the software would just magically choose the right version to use.
How could I do the same? The human voice is a sound wave and a rather well-formed wave as well. It is roughly the composition of a finite number of nice sine waves. And when you integrate the displacement/time function of such a wave for a long time you shall get something close to zero (at most the area under half of the biggest wave). Except when there is a shift in the wave…
This gives a usable idea: decode the files before playback with both algorithms integrate their output for the whole time and chose the one whose value is smaller. Unfortunately parsing files such a way is not an option in our case, it has to be done on the fly. The best I came up with is:
- Chose one of the algorithms for the decoding output, but decode the input with the other as well, integrate both outputs on the go
- If the integrator’s value of the current algorithms exceeds a certain threshold, check the other version’s accumulator and switch if that is better
- If the other integrator’s value isn’t significantly better than reset the decoder state
But we need a good magic number for the algorithm swapping threshold. It shall be high enough that no unnecessary swaps happen and low enough to swap algorithms before the quality drop would be audible. Fortunately the accumulator value starts to skyrocket way before any quality drop could actually happen. After analizing the involved measures in several files 4000000 seemed a good choice. This is my github fork of libsndfile
We have never again had any adpcm decoder related quality issues.